1、背景
漏洞挖掘是安全中比较核心的一个方向,无论是个人安全爱好者的研究还是企业的安全建设很多工作都是围绕漏洞来做的。在大型甲方公司中负责漏洞挖掘和发现的团队通常是SDL或者现在叫DevSecOps,每一个产品发布之前至少要对其做黑盒和白盒两个方面的检测。
无论是黑盒与白盒很重要的一点就是要对其实现自动化,这一点已经有很多了研究成果,包括一些优秀的开源项目。本文探讨一种深度学习算法在白盒代码审计中的利用方式,尝试使用算法检测源代码中的漏洞。这是很久之前做的实验,只是现在整理了一下,可能思路已经陈旧了。
一、漏洞挖掘概述
漏洞挖掘的手法主要分为两个:一是黑盒测试; 二是白盒测试。黑盒测试:也称功能测试,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,对程序接口进行测试。


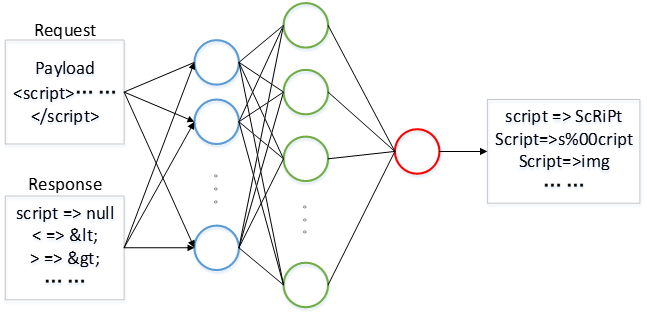
算法会根据上一次请求的Payload和Response生成一个新的Payoad,这其实是模拟了人测试的过程,比如当我们输入进行XSS漏洞测试时,一些符号在输出时被转码,常规的扫描器就是认为此次测试失败了,要换一个新的Payload,而此模型会根据返回结果尝试生成一个可以绕过的Payload,这也就是其智能化的体现。由于本文主要探讨白盒的漏洞挖掘,此模型不详细介绍,感兴趣可以在其github上了解项目细节。
二、基于深度学习的代码审计模型
2.1 代码审计常规流程
在引入算法之前,我们先来回顾一下一个正常的人工审计流程是怎样的,大体可以分为以下四步(可能每个人的习惯不同,会有差异):
- 首先要能理解代码
- 寻找输入点和危险函数
- 确定代码漏洞利用的代码路径(ROC链)
- 对代码路径进行测试
以下面这段代码为例
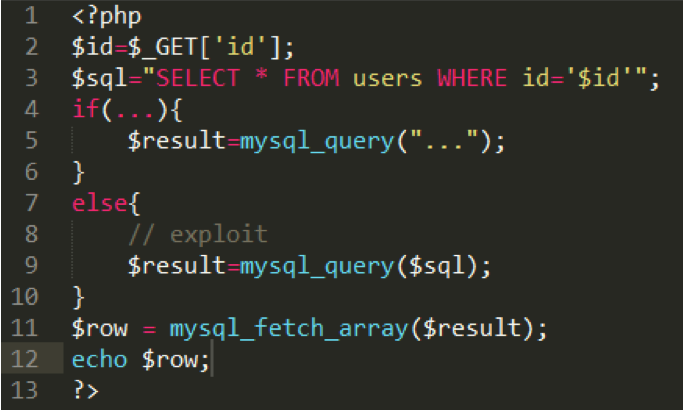
对应于上面四个步骤,
1、理解代码:
这是一段数据库查询的PHP代码,它会显示数据库的查询结果
2、输入点和危险函数:
id=_GET[‘id’];
mysql_query
3、确定漏洞代码路径
2->3->9->11->12
4、代码测试:
-1’ union select database() —+
结果:当if条件不满足时存在SQL注入漏洞。
使用算法无论是解决什么问题,本质都是学习人类的经验来模拟人类进行决策。那么上面四个步骤适合应用算法的实际上是第三步,我们给算法一个代码执行路径,让它判断是否可以漏洞利用。
2.2 算法的选择
代码不同于一般的字符串,它的字符与字符之间、行与行之间、函数与函数之间甚至文件与文件之间都是有关系的,这种上下文关系使得我们不能像处理离散值那样简单的切分后直接抛给任意一个模型。我们希望算法能够学习向量不同维度之间关系,即是由字符转换成数字后,仍然不损失代码的语义逻辑。
这个问题可以参考一个有趣的项目:Screenshot-to-code,此项目是以前端图片为输入,通过算法生成前端代码。
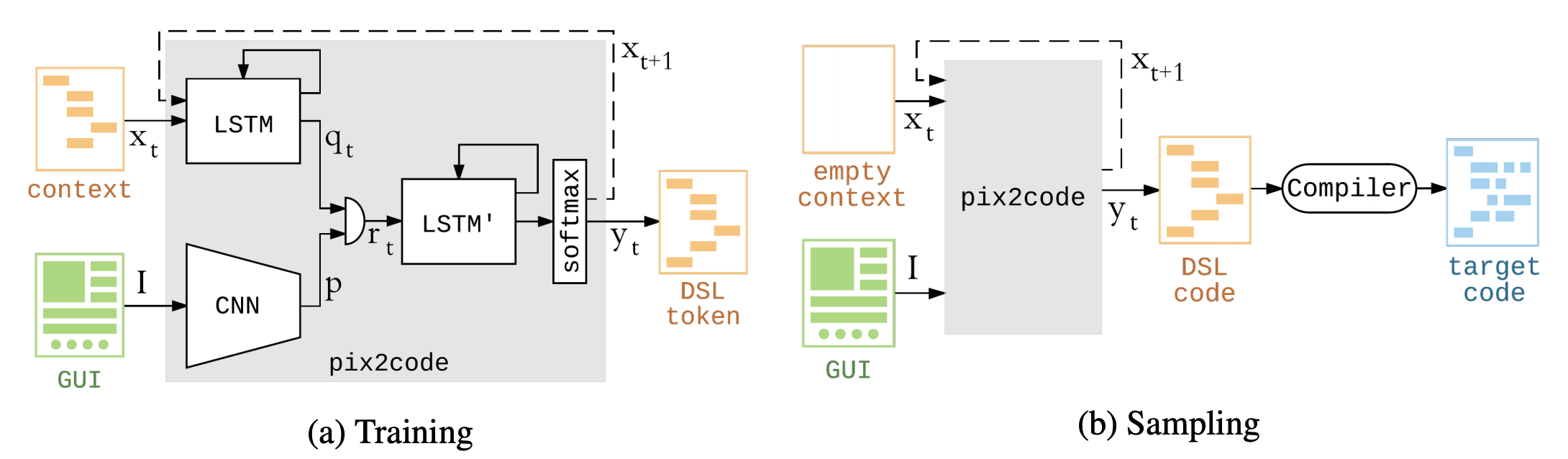
论文下载地址:https://arxiv.org/pdf/1705.07962.pdf
模型和数据集下载地址:https://github.com/tonybeltramelli/pix2code
模型视频演示地址:https://uizard.io/research#pix2code
2.2 数据处理
数据处理的本质其实是模拟人的思路去解析代码,但是要把代码转换成模型可识别的数字向量,这里我们分成下面几个步骤。
Step1:搜索可疑漏洞点
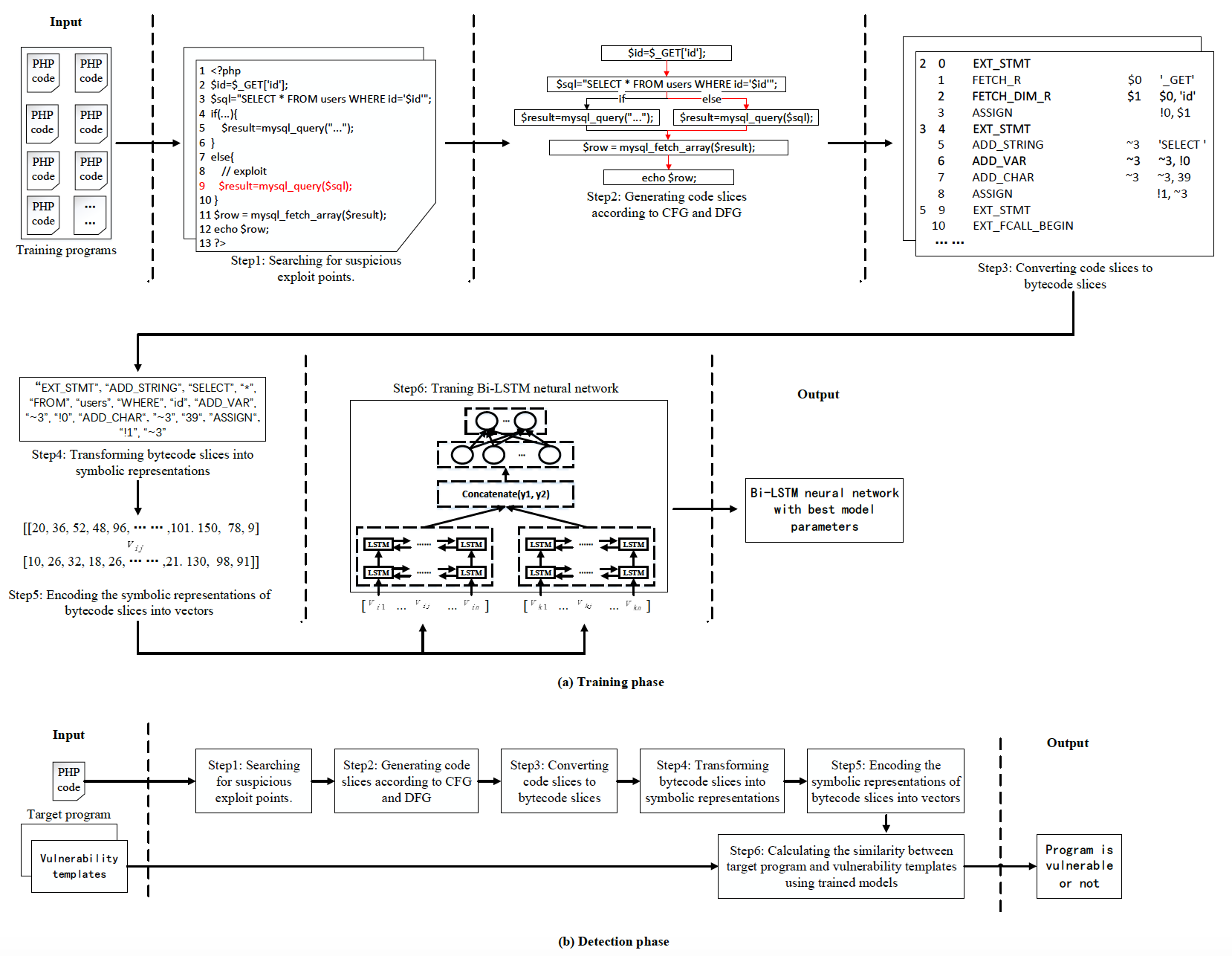
为了确定漏洞的大概位置,首先要搜索可疑漏洞点,也就是指漏洞最终触发的地方。它可能是一些函数或者特殊的代码关键字,比如执行SQL语句的函数或者一些HTML tags(HTML标签,如<.script>、等),它们分别表示SQL注入和XSS漏洞的漏洞点。以2.1 节中的图片为例,我们认为可疑漏洞点就是第9行。
Step2:生成代码数据流
根据代码数据流进行变量追踪是很多白盒检测工具的原理,我们也需要代码的执行流程进行分析,以数据流为单位进行漏洞检测。而不是直接将源代码作为直接切分成字符串,这样会破坏代码的语义,也就失去了漏洞检测的依据。
下图展示了对PHP源代码使用图谱分析生成数据流的流程图,源代码会首先根据上述算法生成图谱,然后根据图的路径提取出多个代码切片。中间部分是代码图谱,可以看到其输入是id=_GET[‘id’],含义是获取HTTP(S)数据包URI中的id参数值,图的输出是echo $row,也就是常见的输出语句。图中示例代码根据控制流可以分成黑色和红色两个代码执行路径,其中红色执行路径存在可疑漏洞点且有用户可控的输入变量,因此将其数据流提取出来,组成代码切片。
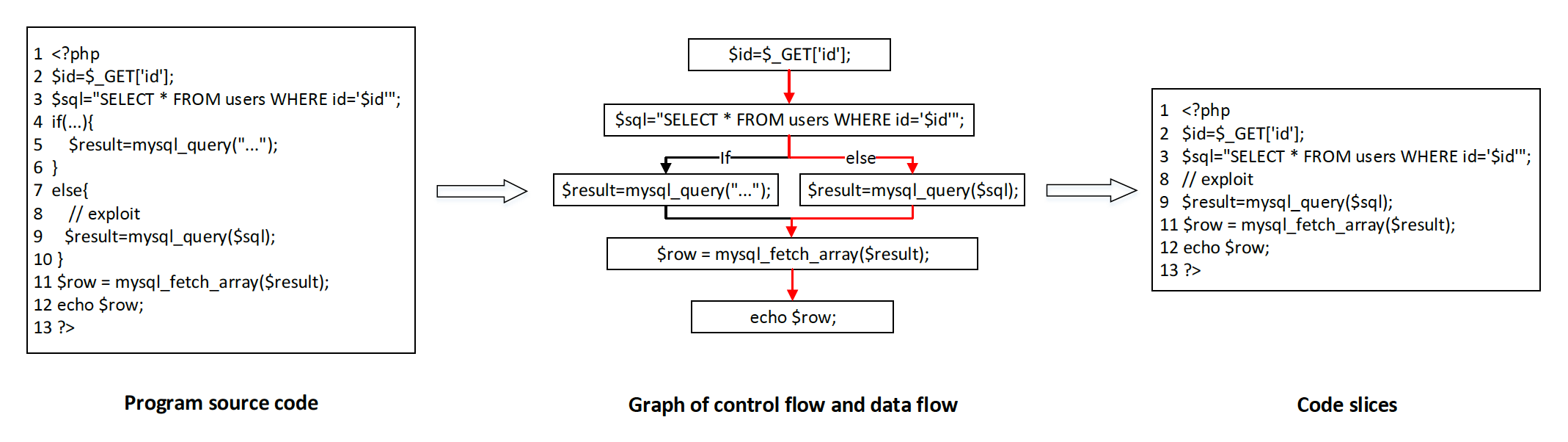
Step3:生成字节码切片
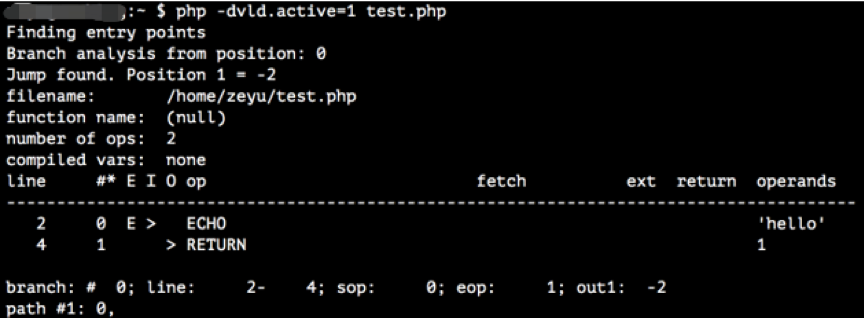
每一种语言都有其对应的编码规范,但是在实际编程中即使是同一功能点不同的开发人员也可能写出风格完全不同的源代码。这些差异导致算法在学习源代码级别的特征的时候容易被干扰,极有可能使得模型过于拟合训练集,当测试集或待检测的目标源代码风格与训练集不一致时模型很容易误判,也就是出现过拟合现象。因此使用源代码级别的特征进行漏洞挖掘存在一定先天劣势,为了解决这个问题我们将代码图谱中提取的源代码切片转换成字节码切片。每种语言有各自的转换方式,PHP可使用自身的拓展VLD(Vulcan Logic Dumper)进行转换,安装完成之后使用命令运行即可,效果如下图所示。

Step4:生成字符向量
深度神经网络一般只能接收数字向量作为输入,因此要采取合适的编码方式将字节码符号转换成数字向量。首先,要对字节码切片进行一些预处理。在字节码字符中有些是被URL编码过的,需要对其进行解码。再以源代码的行为单位,每一行对应若干行字节码切片,将这若干行字节码片段转换成字符序列。具体操作步骤以上图的第3行为例,源代码为:
$sql="SELECT * FROM users WHERE id=’$id’";
其对应的字节码转换成字符序列为:
“EXT_STMT”, “ADD_STRING”, “SELECT”, “*”, “FROM”, “users”, “WHERE”, “id”, “ADD_VAR”, “~ 3”, “!0”, “ADD_CHAR”, “~ 3”, “39”, “ASSIGN”, “!1”, “~ 3”
Step5:生成数字向量
然后使用word2vec,将词序列转换成数字向量。word2vec是词嵌入方法的一种,本质上是简化的神经网络,通过训练可以得到当前词与上下文词的关系模型,模型的权重参数即是当前词的数字编码结果,一般是隐藏层的权重矩阵。使用word2vec获得的数字向量可以在保留词上下文关系的前提下简化向量维度,避免维度灾难。在代码数据中,word2vec转换得出的数字向量包含了变量在个语句传递的关系,对深度学习模型识别漏洞特征具有非常大的帮助。
2.3 模型设计
这里尝试过两种模型,一是单输入和单输出的检测模型,输入一个代码片段,输出是否存在漏洞;二是尝试了一种孪生网络,双输入和单输出,输入两个代码片段,输出两者的相似度,通过相似度的值判断是否存在漏洞。
单网络模型
孪生网络模型
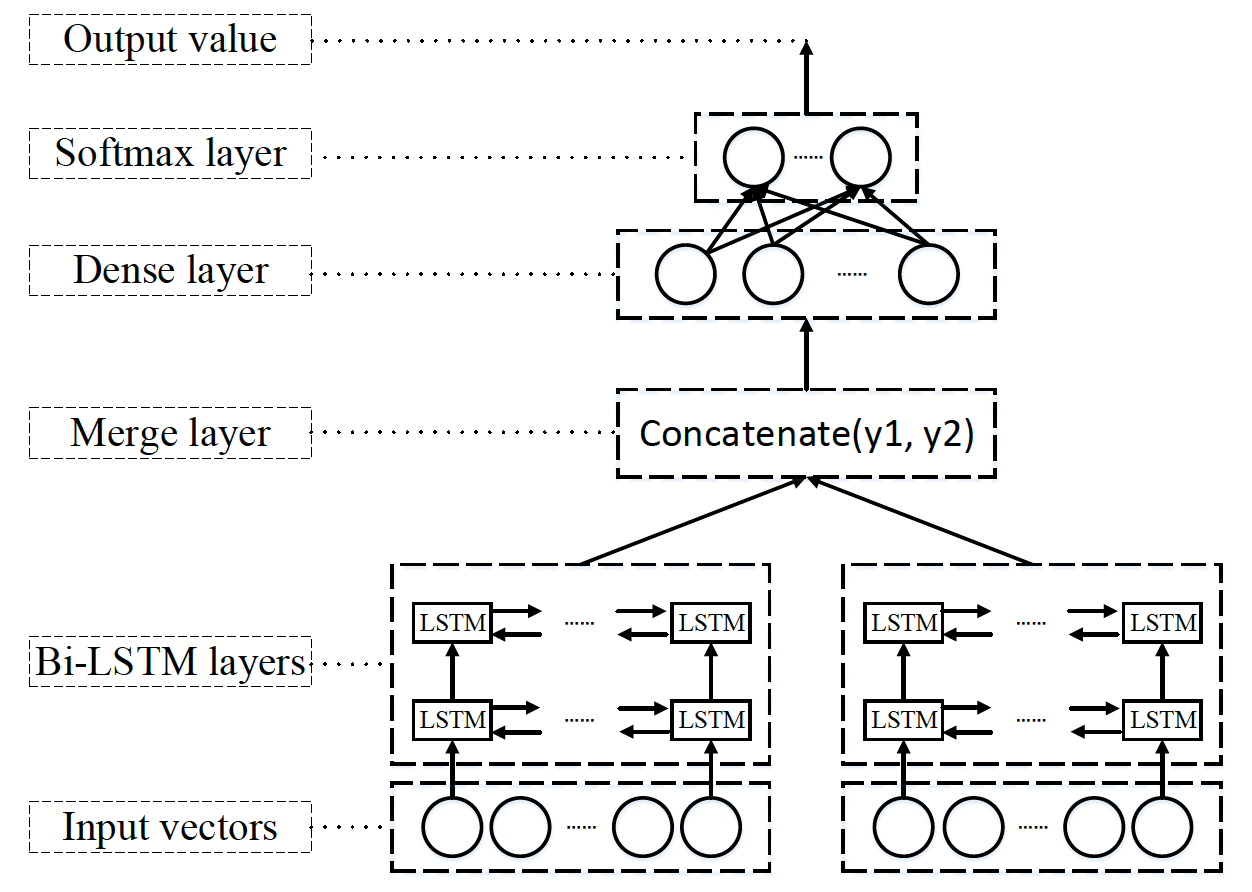
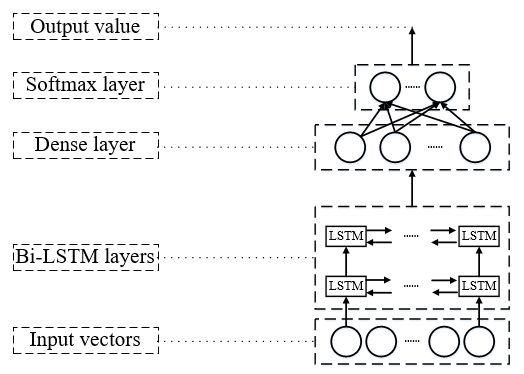
方案二的模型是基于Bi-LSTM构造的孪生网络,模型的核心方法是计算待检测的目标代码和漏洞模板之间相似度,根据相似度是否超过阈值判定是否存在漏洞。因此,本文的神经网络模型输入为两个数字向量,输出为一个0到1之间的相似度值。如下图所示为神经网络的结构图,它有两个Bi-LSTM层,一个Merge layer(融合层),一个Dense layer(全连接层)和一个Softmax层,最终使用一个Model进行封装,使得左右两个网络能够共享权值。Bi-LSTM层包含了LSTM神经元,将它们进行前后双向链接,能够前后双向的传播误差,提高算法准确度;融合层会将Bi-LSTM层的两个输出融合成一个张量;全链接层用于减少张量的维度;Softmax层将低维张量作为输入,然后输出一个0到1之间数值,代表了最初两个向量的相似度。相似度越高值接近1,相似度越低值越接近于0。为了适应模型的输入结构,要将训练或测试数据构造成一个元组(X1,X2)。第一维是漏洞模板,第二维是训练或测试数据,分别输入到两个分支网络中。模型使用Adam优化算法以及二元交叉熵(binary_crossentropy)损失函数,其损失值不为负,Adam对其的优化是一个由较高的正值逐渐向0靠近的过程。
2.4 系统流程
相对于两种模型,其数据处理流程大致是相同的,只是在模型输入和结果判定上存在一定区别。单网络模型较好理解,输入一个代码片段,输出是否存在漏洞,这里重点介绍孪生网络模型的流程。
模型的过程主要分为两个阶段,训练阶段和检测阶段。两个阶段的处理过程是一致的,不过训练阶段的输出是模型,检测阶段的输出是漏洞检测结果。如下图所示(图中代码数据以PHP语言为例)是整个模型结构。
其中S表示相似度均值,N表示特定类型的漏洞模板数量,BLNN表示Bi-LSTM神经网络,T_i表示某一个具体的模板,P表示待检测的目标代码(本文以PHP为例)。BLNN是的输出是0(不相似)到1(相似)之间的一个值,当整体的相似度均值S超过了设定的阈值就判定存在漏洞,这里的初始阈值本文设定为0.5,用户可以根据使用情况在系统配置中进行修改。
在本文的实验中,漏洞模板本质是确定存在漏洞的字节码切片,每种类型的漏洞会有多个模板。判定是否存在某个类型的漏洞时要和该类型的模板都计算一次相似度,仅此这个模型相对于单网络模型是非常耗时的。
三、算法实验
实验以P(准确率))、R(召回率)、F1值、假阴率(FNR)和假阳率(FPR)几个指标作为评估依据。实验数据来自美国国家漏洞库的
Sard 项目,该项目有大量的漏洞样例,并且每个都标记了CWE编号,也就是漏洞类型。经过统计,一共收集了18989个样本,其中SQL注入漏洞样本912个,XSS漏洞样本4352个,剩下的13725个为不存在漏洞的样本。
根据前面提到的数据处理过程,将采集到的数据转换成数字向量。本文根据漏洞类型不同将数据集分成SQL-SET、XSS-SET和MUL-SET三个,MUL-SET是SQL和XSS漏洞数据的混合数据集,以此来检验模型对不同漏洞的区分能力。在SQL-SET数据集中有1032509个token,每一个token代表向量中的一个词,去重之后有182个;在XSS-SET数据中有510252个token,去重之后有168个;MUL-SET是前两者的和。这里的每一个token都是源代码中的一个关键词、变量名或者函数名,当以空格分割后会产生大量的token,但是转换成字节码后许多自定义名称或者程序关键词都被自动编码了,这使得字节码层面的token种类大幅减少。下表展示了三个数据集中字节码切片的统计情况,可以看到每一种类型漏洞数据的无漏洞样本要多于有漏洞的样本,这是数据采集中的正负样本不均衡的现象,会给模型训练带来一定负面影响。本实验会从三个数据集随机抽取10%的数据作为测试集,剩余的作为训练集用于模型训练。
| 数据集 | 字节码切片 | 漏洞字节码切片 | 无漏洞字节码切片 |
|---|---|---|---|
| SQL-SET | 8904 | 912 | 7992 |
| XSS-SET | 10085 | 4352 | 5733 |
| MUL-SET | 18989 | 5264 | 13725 |
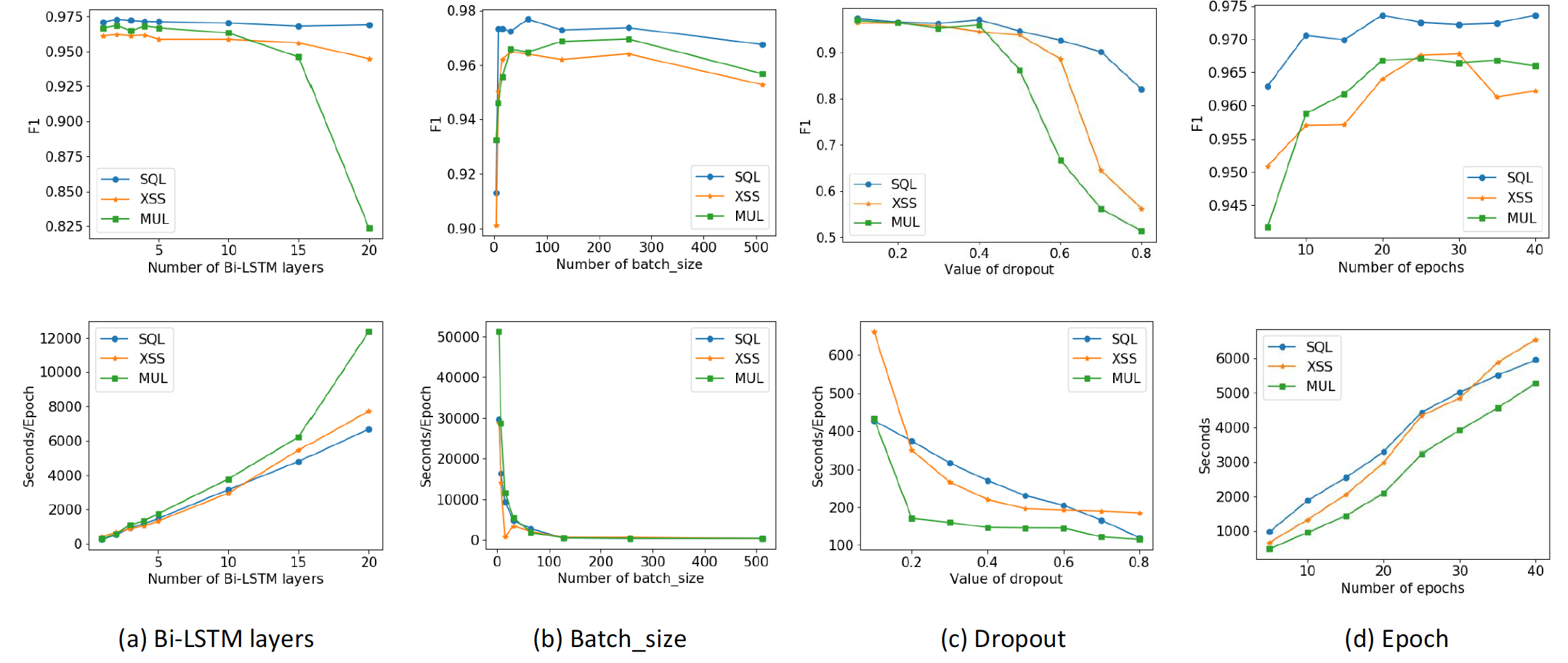
如下图所示是训过中参数调优的过程,图中重点描述了几个核心参数随着F1值变化而变化的过程,根据参数与F1值的变化关系,综合选定参数值。
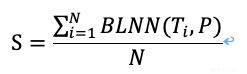
| 数据集 | P(%) | R(%) | F1(%) | FPR(%) | FNR(%) |
|---|---|---|---|---|---|
| SQL-SET | 78.04 | 100.0 | 88.04 | 3.13 | 0.00 |
| XSS-SET | 99.02 | 92.22 | 95.50 | 0.70 | 7.78 |
| MUL-SET | 85.76 | 97.99 | 91.44 | 6.26 | 2.01 |
单网络模型的数据丢失了,没有找到备份,总体上是低于孪生网络模型的。不过若真正在生产环境下使用,孪生网络可信度比较低,主要是因为其检测速度太慢。