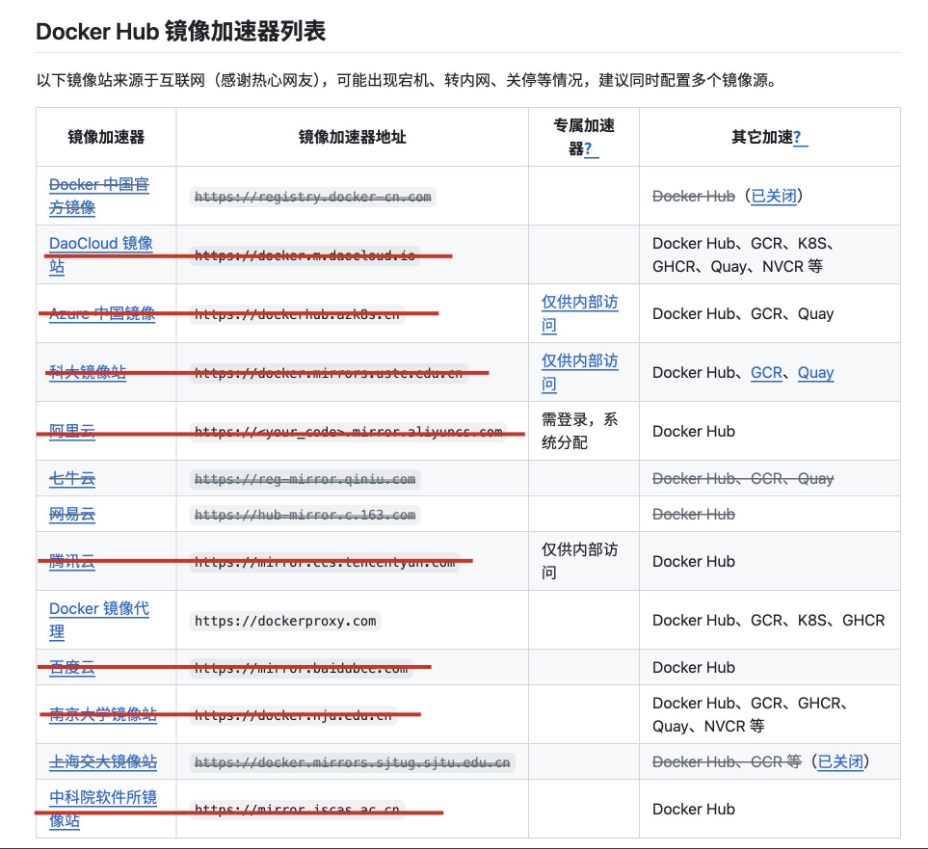
关于日志的一些问题:
单个文件过大会影响写入效率,所以会做拆分,但是到多大拆分? 最多保留几个日志文件?最多保留多少天,要不要做压缩处理?
一般都使用 lumberjack这个库完成上述这些操作
lumberjack
//info文件writeSyncer
infoFileWriteSyncer := zapcore.AddSync(&lumberjack.Logger{
Filename: "./log/info.log", //日志文件存放目录,如果文件夹不存在会自动创建
MaxSize: 2, //文件大小限制,单位MB
MaxBackups: 100, //最大保留日志文件数量
MaxAge: 30, //日志文件保留天数
Compress: false, //是否压缩处理
})
infoFileCore := zapcore.NewCore(encoder, zapcore.NewMultiWriteSyncer(infoFileWriteSyncer, zapcore.AddSync(os.Stdout)), lowPriority) //第三个及之后的参数为写入文件的日志级别,ErrorLevel模式只记录error级别的日志
//error文件writeSyncer
errorFileWriteSyncer := zapcore.AddSync(&lumberjack.Logger{
Filename: "./log/error.log", //日志文件存放目录
MaxSize: 1, //文件大小限制,单位MB
MaxBackups: 5, //最大保留日志文件数量
MaxAge: 30, //日志文件保留天数
Compress: false, //是否压缩处理
})
测试日志到达指定大小后自动会切分

例如,当info级别的日志文件到达2M时,会根据当时的时间戳,切分出一个info-2023-04-13T05-27-18.296.log。 后续新写入的info级别的日志将写入到info.log,直到又到达2M,继续会切分。
测试日志到达指定最大保留日志文件数量后,将作何操作
清掉log文件夹,修改error日志配置:
errorFileWriteSyncer := zapcore.AddSync(&lumberjack.Logger{
Filename: "./log/error.log", //日志文件存放目录
MaxSize: 1, //文件大小限制,单位MB
MaxBackups: 3, //最大保留日志文件数量
MaxAge: 30, //日志文件保留天数
Compress: false, //是否压缩处理
})
代码中只打印error日志,执行代码 进行观察

继续执行

继续执行


可见最早拆分出的那个error-2023-04-13T05-40-48.715.log文件不见了~
继续执行,切分出来的文件数量,也会始终保持3个
完整变化图:

测试压缩处理的效果
清掉log文件夹,修改error日志配置:
errorFileWriteSyncer := zapcore.AddSync(&lumberjack.Logger{
Filename: "./log/error.log", //日志文件存放目录
MaxSize: 5, //文件大小限制,单位MB
MaxBackups: 10, //最大保留日志文件数量
MaxAge: 30, //日志文件保留天数
Compress: false, //是否压缩处理
})
代码中只打印error日志,执行代码,循环10000000次, 进行观察

不压缩共占用814M存储空间
清掉log文件夹,修改Compress字段为true,执行代码:

启用压缩后,仅占用了30M磁盘空间!
不太好的地方就是不方便直接查看了,需要解压后查看。但大大省了所占用的空间
lumberjack这个库目前只支持按文件大小切割(按时间切割效率低且不能保证日志数据不被破坏,详情见https://github.com/natefinch/lumberjack/issues/54)
想按日期切割可以使用github.com/lestrrat-go/file-rotatelogs这个库(目前不维护了)
file-rotatelogs实现按时间的切割
注意:
github.com/lestrrat-go/file-rotatelogs(2021年后不更新了) 和 github.com/lestrrat/go-file-rotatelogs(2018年以后就不更新了) 两个不一样。。前面那个是更新的,作者是一个人…
(有一个linux系统上的日志工具,也叫logrotate)
logrotate 是一个用于日志文件轮换的 Go 语言库,支持按时间轮换、按文件大小轮换和按行数轮换。还支持在轮换时压缩文件、删除旧文件、给文件添加时间戳等功能
用zap和go-file-rotatelogs实现日志的记录和日志按时间分割
WithRotationCount和WithMaxAge两个选项不能共存,只能设置一个(都设置编译时不会出错,但运行时会报错。也是为了防止影响切分的处理逻辑):
panic: options MaxAge and RotationCount cannot be both set
package main
import (
"fmt"
"io"
"net/http"
"time"
rotatelogs "github.com/lestrrat-go/file-rotatelogs"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
// 使用file-rotatelogs做切分
var sugarLogger *zap.SugaredLogger
func main() {
fmt.Println("shuang提示:begin main")
InitLogger()
defer sugarLogger.Sync()
for i := 0; i < 100000; i++ {
simpleHttpGet("www.cnblogs.com")
simpleHttpGet("https://www.baidu.com")
}
}
// 例子,http访问url,返回状态
func simpleHttpGet(url string) {
fmt.Println("begin simpleHttpGet:" + url)
sugarLogger.Debugf("Trying to hit GET request for %s", url)
resp, err := http.Get(url)
if err != nil {
sugarLogger.Errorf("Error fetching URL %s : Error = %s", url, err)
} else {
sugarLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)
resp.Body.Close()
}
}
func InitLogger() {
encoder := getEncoder()
//两个interface,判断日志等级
//warnlevel以下归到info日志
infoLevel := zap.LevelEnablerFunc(func(lvl zapcore.Level) bool {
return lvl < zapcore.WarnLevel
})
//warnlevel及以上归到warn日志
warnLevel := zap.LevelEnablerFunc(func(lvl zapcore.Level) bool {
return lvl >= zapcore.WarnLevel
})
infoWriter := getLogWriter("/Users/fliter/zap-demo/demo2-log/info")
warnWriter := getLogWriter("/Users/fliter/zap-demo/demo2-log/warn")
//创建zap.Core,for logger
core := zapcore.NewTee(
zapcore.NewCore(encoder, infoWriter, infoLevel),
zapcore.NewCore(encoder, warnWriter, warnLevel),
)
//生成Logger
logger := zap.New(core, zap.AddCaller())
sugarLogger = logger.Sugar()
}
// getEncoder
func getEncoder() zapcore.Encoder {
encoderConfig := zap.NewProductionEncoderConfig()
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
return zapcore.NewConsoleEncoder(encoderConfig)
}
// 得到LogWriter
func getLogWriter(filePath string) zapcore.WriteSyncer {
warnIoWriter := getWriter(filePath)
return zapcore.AddSync(warnIoWriter)
}
// 日志文件切割
func getWriter(filename string) io.Writer {
//保存日志30天,每1分钟分割一次日志
hook, err := rotatelogs.New(
filename+"_%Y-%m-%d %H:%M:%S.log",
// 为最新的日志建立软连接,指向最新日志文件
rotatelogs.WithLinkName(filename),
// 清理条件: 将已切割的日志文件按条件(数量or时间)直接删除
//--- MaxAge and RotationCount cannot be both set 两者不能同时设置
//--- RotationCount用来设置最多切割的文件数(超过的会被 从旧到新 清理)
//--- MaxAge 是设置文件清理前的最长保存时间 最小分钟为单位
//--- if both are 0, give maxAge a default 7 * 24 * time.Hour
// WithRotationCount和WithMaxAge两个选项不能共存,只能设置一个(都设置编译时不会出错,但运行时会报错。也是为了防止影响切分的处理逻辑)
//rotatelogs.WithRotationCount(10), // 超过这个数的文件会被清掉
rotatelogs.WithMaxAge(time.Hour*24*30), // 保存多久(设置文件清理前的最长保存时间 最小分钟为单位)
// 切分条件(将日志文件做切割;WithRotationTime and WithRotationSize ~~两者任意一个条件达到都会切割~~)
// 经过亲测后发现,如果日志没有持续增加,WithRotationTime设置较小(如10s),并不会按WithRotationTime频次切分文件。当日志不停增加时,会按照WithRotationTime设置来切分(即便WithRotationTime设置的很小)
rotatelogs.WithRotationTime(time.Second*10), // 10秒分割一次(设置日志切割时间间隔,默认 24 * time.Hour)
rotatelogs.WithRotationSize(int64(1*1024*1024*1024)), // 文件达到多大则进行切割,单位为 bytes;
)
if err != nil {
panic(err)
}
return hook
}
验证其切分功能:
将触发切分的文件大小设置得很大(110241024*1024 Byte即1 GB),切分时间设置得较小(10秒分割一次),执行代码,可以观察到日志文件的变化:


再将触发切分的文件大小设置得很小(1102450 Byte即50 KB),切分时间设置得较大(24h分割一次),执行代码,清掉之前的日志,再观察到日志文件的变化:


将触发切分的文件大小设置得很小(1102435 Byte即35 KB),同时切分时间也设置得很小(10s分割一次),执行代码,清掉之前的日志,再观察到日志文件的变化:

当前日志容量大于配置的容量时,会生成新的日志文件,如果时间一样,在时间后缀后面会自动加上一个数字后缀,以此区分同一时间的不同日志文件,如果时间不一样,则生成新的时间后缀文件 (golang实现分割日志)
日志文件中是会出现有的命中时间规则,有的命中文件大小规则的情况,两者命名格式不同,参考上图
切分之后执行压缩命令

默认是没有的,不像lumberjack那样提供Compress选项
前面所提的还支持在轮换时压缩文件、删除旧文件、给文件添加时间戳等功能需要自己实现。 提供了一个WithHandler回调函数,发生切分后会触发该函数,可以在其中进项压缩等操作

改一下代码(不再请求网站因为速度太慢,直接在for里面写日志)
不启用压缩:

启用压缩,效果显著:

相关代码:
package main
import (
"archive/zip"
"fmt"
"io"
"net/http"
"os"
"path/filepath"
"reflect"
"time"
"github.com/davecgh/go-spew/spew"
rotatelogs "github.com/lestrrat-go/file-rotatelogs"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
// 使用file-rotatelogs做切分
var sugarLogger *zap.SugaredLogger
func main() {
fmt.Println("shuang提示:begin main")
InitLogger()
defer sugarLogger.Sync()
for i := 0; i < 10000000; i++ {
sugarLogger.Infof("测试压缩后少占用的空间,这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本这是填充文本,i is %d", i)
//simpleHttpGet("www.cnblogs.com", i)
//simpleHttpGet("https://www.baidu.com", i)
}
time.Sleep(10000e9)
}
// 例子,http访问url,返回状态
func simpleHttpGet(url string, i int) {
//fmt.Println("begin simpleHttpGet:" + url)
sugarLogger.Debugf("Trying to hit GET request for %s, i is %d", url, i)
resp, err := http.Get(url)
if err != nil {
sugarLogger.Errorf("Error fetching URL %s : Error = %s, i is %d", url, err, i)
} else {
sugarLogger.Infof("Success! statusCode = %s for URL %s,i is %d", resp.Status, url, i)
resp.Body.Close()
}
}
func InitLogger() {
encoder := getEncoder()
//两个interface,判断日志等级
//warnlevel以下归到info日志
infoLevel := zap.LevelEnablerFunc(func(lvl zapcore.Level) bool {
return lvl < zapcore.WarnLevel
})
//warnlevel及以上归到warn日志
warnLevel := zap.LevelEnablerFunc(func(lvl zapcore.Level) bool {
return lvl >= zapcore.WarnLevel
})
infoWriter := getLogWriter("/Users/fliter/zap-demo/demo2-log/info")
warnWriter := getLogWriter("/Users/fliter/zap-demo/demo2-log/warn")
//创建zap.Core,for logger
core := zapcore.NewTee(
zapcore.NewCore(encoder, infoWriter, infoLevel),
zapcore.NewCore(encoder, warnWriter, warnLevel),
)
//生成Logger
logger := zap.New(core, zap.AddCaller())
sugarLogger = logger.Sugar()
}
// getEncoder
func getEncoder() zapcore.Encoder {
encoderConfig := zap.NewProductionEncoderConfig()
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
return zapcore.NewConsoleEncoder(encoderConfig)
}
// 得到LogWriter
func getLogWriter(filePath string) zapcore.WriteSyncer {
warnIoWriter := getWriter(filePath)
return zapcore.AddSync(warnIoWriter)
}
// 日志文件切割
func getWriter(filename string) io.Writer {
//保存日志30天,每1分钟分割一次日志
hook, err := rotatelogs.New(
filename+"_%Y-%m-%d %H:%M:%S.log",
// 为最新的日志建立软连接,指向最新日志文件
rotatelogs.WithLinkName(filename),
// 清理条件: 将已切割的日志文件按条件(数量or时间)直接删除
//--- MaxAge and RotationCount cannot be both set 两者不能同时设置
//--- RotationCount用来设置最多切割的文件数(超过的会被 从旧到新 清理)
//--- MaxAge 是设置文件清理前的最长保存时间 最小分钟为单位
//--- if both are 0, give maxAge a default 7 * 24 * time.Hour
// WithRotationCount和WithMaxAge两个选项不能共存,只能设置一个(都设置编译时不会出错,但运行时会报错。也是为了防止影响切分的处理逻辑)
//rotatelogs.WithRotationCount(10), // 超过这个数的文件会被清掉
rotatelogs.WithMaxAge(time.Hour*24*30), // 保存多久(设置文件清理前的最长保存时间 最小分钟为单位)
// 切分条件(将日志文件做切割;WithRotationTime and WithRotationSize ~~两者任意一个条件达到都会切割~~)
// 经过亲测后发现,如果日志没有持续增加,WithRotationTime设置较小(如10s),并不会按WithRotationTime频次切分文件。当日志不停增加时,会按照WithRotationTime设置来切分(即便WithRotationTime设置的很小)
rotatelogs.WithRotationTime(time.Second*10), // 10秒分割一次(设置日志切割时间间隔,默认 24 * time.Hour)
rotatelogs.WithRotationSize(int64(1*1024*35000*1024)), // 文件达到多大则进行切割,单位为 bytes;
// 其他可选配置
//default: rotatelogs.Local ,you can set rotatelogs.UTC
//rotatelogs.WithClock(rotatelogs.UTC),
//rotatelogs.WithLocation(time.Local),
//--- 当rotatelogs.New()创建的文件存在时,强制创建新的文件 命名为原文件的名称+序号,如a.log存在,则创建创建 a.log.1
//rotatelogs.ForceNewFile(),
rotatelogs.WithHandler(rotatelogs.Handler(rotatelogs.HandlerFunc(func(e rotatelogs.Event) {
if e.Type() != rotatelogs.FileRotatedEventType {
return
}
fmt.Println("切割完成,进行打包压缩操作")
spew.Dump("e is:", e)
prevFile := e.(*rotatelogs.FileRotatedEvent).PreviousFile()
if prevFile != "" {
// 进行压缩
paths, fileName := filepath.Split(prevFile)
//_ = paths
//err := Zip("archive.zip", paths, prevFile)
err := ZipFiles(paths+fileName+".zip", []string{prevFile})
fmt.Println("err is", err)
if err == nil {
os.RemoveAll(prevFile)
}
}
fmt.Println("e的类型为:", reflect.TypeOf(e))
fmt.Println("------------------")
fmt.Println()
fmt.Println()
fmt.Println()
//ctx := CleanContext{
// Dir: LogsConfig.LogOutputDir,
// DirMaxSizeG: LogsConfig.LogDirMaxSizeG,
// DirMaxCount: LogsConfig.LogDirMaxFileCount,
//}
//strategyOne := CleanStrategyOne{}
//result, err := NewCleanStrategy(&ctx, &strategyOne).
// Clean().
// Result()
//Warn("文件切割,清理文件策略one已经执行完毕; 结果:%v; 错误:%v", result, err)
}))),
)
if err != nil {
panic(err)
}
return hook
}
// ZipFiles compresses one or many files into a single zip archive file.
// Param 1: filename is the output zip file's name.
// Param 2: files is a list of files to add to the zip.
func ZipFiles(filename string, files []string) error {
newZipFile, err := os.Create(filename)
if err != nil {
return err
}
defer newZipFile.Close()
zipWriter := zip.NewWriter(newZipFile)
defer zipWriter.Close()
// Add files to zip
for _, file := range files {
if err = AddFileToZip(zipWriter, file); err != nil {
return err
}
}
return nil
}
func AddFileToZip(zipWriter *zip.Writer, filename string) error {
fileToZip, err := os.Open(filename)
if err != nil {
return err
}
defer fileToZip.Close()
// Get the file information
info, err := fileToZip.Stat()
if err != nil {
return err
}
header, err := zip.FileInfoHeader(info)
if err != nil {
return err
}
// Using FileInfoHeader() above only uses the basename of the file. If we want
// to preserve the folder structure we can overwrite this with the full path.
header.Name = filename
// Change to deflate to gain better compression
// see http://golang.org/pkg/archive/zip/#pkg-constants
header.Method = zip.Deflate
writer, err := zipWriter.CreateHeader(header)
if err != nil {
return err
}
_, err = io.Copy(writer, fileToZip)
return err
}
//
//// Zip compresses the specified files or dirs to zip archive.
//// If a path is a dir don't need to specify the trailing path separator.
//// For example calling Zip("archive.zip", "dir", "csv/baz.csv") will get archive.zip and the content of which is
//// baz.csv
//// dir
//// ├── bar.txt
//// └── foo.txt
//// Note that if a file is a symbolic link it will be skipped.
//
//// https://blog.csdn.net/K346K346/article/details/122441250
//func Zip(zipPath string, paths ...string) error {
// // Create zip file and it's parent dir.
// if err := os.MkdirAll(filepath.Dir(zipPath), os.ModePerm); err != nil {
// return err
// }
// archive, err := os.Create(zipPath)
// if err != nil {
// return err
// }
// defer archive.Close()
//
// // New zip writer.
// zipWriter := zip.NewWriter(archive)
// defer zipWriter.Close()
//
// // Traverse the file or directory.
// for _, rootPath := range paths {
// // Remove the trailing path separator if path is a directory.
// rootPath = strings.TrimSuffix(rootPath, string(os.PathSeparator))
//
// // Visit all the files or directories in the tree.
// err = filepath.Walk(rootPath, walkFunc(rootPath, zipWriter))
// if err != nil {
// return err
// }
// }
// return nil
//}
//
//func walkFunc(rootPath string, zipWriter *zip.Writer) filepath.WalkFunc {
// return func(path string, info fs.FileInfo, err error) error {
// if err != nil {
// return err
// }
//
// // If a file is a symbolic link it will be skipped.
// if info.Mode()&os.ModeSymlink != 0 {
// return nil
// }
//
// // Create a local file header.
// header, err := zip.FileInfoHeader(info)
// if err != nil {
// return err
// }
//
// // Set compression method.
// header.Method = zip.Deflate
//
// // Set relative path of a file as the header name.
// header.Name, err = filepath.Rel(filepath.Dir(rootPath), path)
// if err != nil {
// return err
// }
// if info.IsDir() {
// header.Name += string(os.PathSeparator)
// }
//
// // Create writer for the file header and save content of the file.
// headerWriter, err := zipWriter.CreateHeader(header)
// if err != nil {
// return err
// }
// if info.IsDir() {
// return nil
// }
// f, err := os.Open(path)
// if err != nil {
// return err
// }
// defer f.Close()
// _, err = io.Copy(headerWriter, f)
// return err
// }
//}
关于压缩:
Golang 学习笔记(五)- archive/zip 实现压缩及解压
更多参考:
zap日志切割,同时支持按日期拆分,也支持按日志固定大小拆分,支持定时清理
[golang log rotate file](https://juejin.cn/s/golang log rotate file)