1.Spark简介
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用****内存并行计算****框架
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集。
1.1 特点
1.运行速度快:Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
2.易用性好:Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
3.通用性强:Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理。
4.随处运行:Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算
1.2 原理简述
Spark 是使用 scala 实现的基于内存计算的大数据开源集群计算环境.提供了 java,scala, python,R 等语言的调用接口.
1.3 Spark核心模块

SparkCore
实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。SparkCore 中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL
是 Spark 用来操作结构化数据的程序包。通过SparkSql,我们可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming
是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib
提供常见的机器学习 (ML) 功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
2.上手使用Spark
2.1 所需环境
Java:jdk1.8
Spark:3.0.0
Maven:3.6.X
Scala-sdk:2.12.11
开发工具:Idea
所需插件:Scala
请注意,Spark 3 通常是使用 Scala 2.12 预先构建的,Spark 3.2+ 提供了额外的预先构建的 Scala 2.13 发行版。
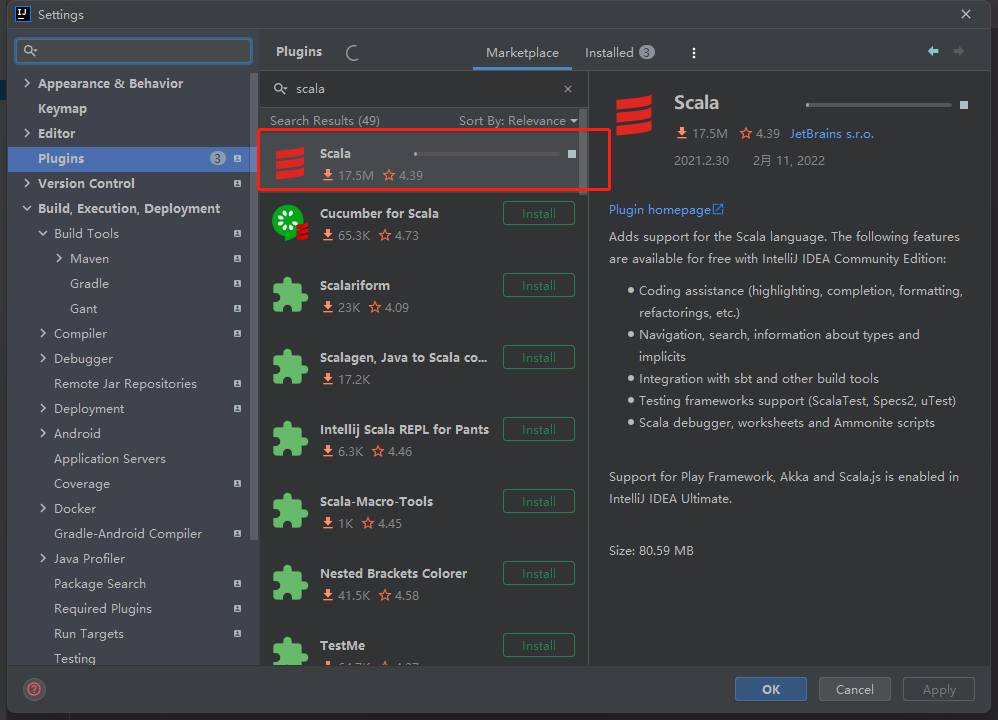
安装好插件我们创建一个新的Maven项目,项目创建好了之后记得去项目管理里面查看是否有sacla-sdk

如果这里没有在项目右键 点击Add Frameword Support

往下拉找到 Scala,如果没有提前下载配置的话可以点击create 直接在idea里面下载配置

2.2 Hello,World!
接下来我们先写个HelloWord测试一下环境是否正常,如果能正确输出 那说明就没问题了
object test {
def main(args: Array[String]): Unit = {
println("Hello, world!")
}
}

2.3 简单案例–单词出现次数统计
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
案例代码:
def main(args: Array[String]): Unit = {
// 建立和Spark的连接
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local")
val sparkContext = new SparkContext(conf)
//读取文件,逐行获取数据
val lines: RDD[String] = sparkContext.textFile("C:\\Users\\21849\\IdeaProjects\\Spark\\Spark-Core\\src\\main\\resources\\word.txt")
//分词
val word: RDD[String] = lines.flatMap(_.split(" "))
//分组
val wordGroup: RDD[(String, Iterable[String])] = word.groupBy(word => word)
//分组聚合 转换为次数统计
val word2Count = wordGroup.map {
case (word, list) => (word, list.size)
}
//输出结果
word2Count.collect().foreach(println)
//关闭连接
sparkContext.stop()
}
运行完就可以在控制台看到我们想要的结果了

2.4 基于Spark实现案例
上面代码都是基于scala来实现的,下面我们通过Spark来实现一次
这里相对于来说没有什么改变,我们可以将之前做聚合的操作换成reduceByKey来实现
// 建立和Spark的连接
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local")
val sparkContext = new SparkContext(conf)
//读取文件,逐行获取数据
val lines: RDD[String] = sparkContext.textFile("C:\\Users\\21849\\IdeaProjects\\Spark\\Spark-Core\\src\\main\\resources\\word.txt")
val words: RDD[String] = lines.flatMap(_.split(" "))
val word2One = words.map(word => (word, 1))
//reduceByKey 相同的key的数据对应的value进行reduce聚合
//word2One.reduceByKey((x,y) => x+y) 改行代码和下面的意思一样 可以简化为下面这行代码的写法
/*
reduceByKey会寻找相同key的数据,当找到这样的两条记录时会对其value(分别记为x,y)做(x,y) => x+y的处理,即只保留求和之后的数据作为value。反复执行这个操作直至每个key只留下一条记录。
*/
word2One.reduceByKey(_ + _).foreach(println)
//关闭连接
sparkContext.stop()
reduceByKey:reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
也就是,groupByKey也是对每个key进行操作,但只生成一个sequence。需要特别注意“Note”中的话,它告诉我们:如果需要对sequence进行aggregation操作(注意,groupByKey本身不能自定义操作函数),那么,选择reduceByKey/aggregateByKey更好。这是因为groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
3.Spark运行环境

3.1 Local模式
想啥呢,你之前一直在使用的模式可不是 Local 模式哟。所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等,之前在 IDEA 中运行代码的环境我们称之为开发环境,不太一样。
3.2 Standalone模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的
集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。