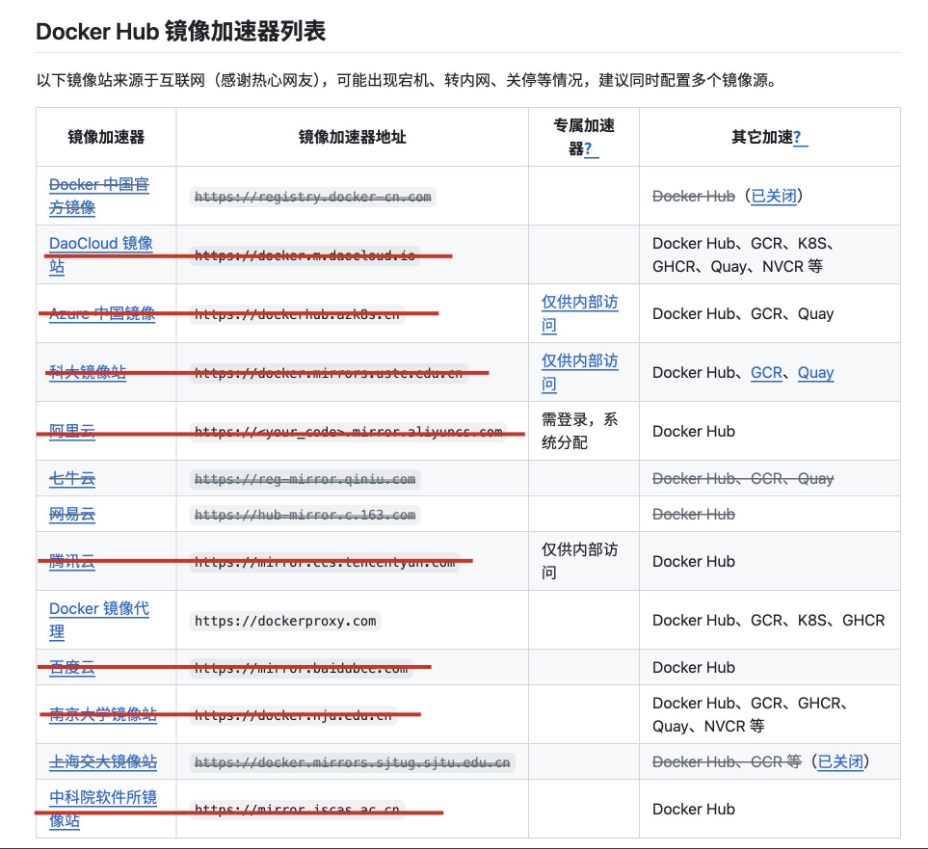
import requests
import json
import re
import os
import threading
def Requests(url):
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'}
n = 0
while True:
n += 1
try:
response = requests.get(url,headers = head,timeout = 10)
except:
pass
else:
if response.status_code == 200:
return response
if n >= 10:
return False
def folder_mkdir():
if os.path.exists(os.getcwd()+'\\pic'):
pass
else:
os.mkdir(os.getcwd()+'\\pic')
folder = os.getcwd()+'\\pic\\'
return folder
def install_img(url,folder,name):
try:
img_content = Requests(url).content
except:
print('错误:{} 名称:{}'.fomat(url,name))
else:
open(folder+name,'wb').write(img_content)
def get_data(item_host_url):
mode = 'thread' #多线程下载模式
folder = folder_mkdir()
item_response = Requests(item_host_url)
if item_response == False:
return
item_response.encoding = 'utf-8'
try:
item_data = re.findall('window.__ssr_data = JSON.parse\("(.*?)"\);\n window._UID_ = \'0\';',item_response.text)[0].replace('\\"','"').replace('u002F','').replace('\\\\','/')
except:
pass
else:
item_img_data = json.loads(item_data,strict=False)['detail']['post_data']['multi']
num = len(os.listdir(folder))
print(num)
for img_data in item_img_data:
img_url = img_data['original_path']
if img_url.find('jpg') >= 0:
img_fomat = '.jpg'
elif img_url.find('png') >= 0:
img_fomat = '.png'
else:
img_fomat = '.jpg'
num += 1
name = str(num)+img_fomat
if mode == 'thread':
t = threading.Thread(target = install_img,args = (img_url,folder,name)).start()
while True:
if len(threading.enumerate()) <= 25:
break
else:
install_img(img_url,folder,name)
if __name__ == '__main__':
item_host_url = 'https://bcy.net/item/detail/6781452585363577870?_source_page=cos'
get_data(item_host_url)
print('下载完成')
Requests()
import requests
def Requests(url):
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'}
n = 0 #计算请求次数,错误过多则跳过此链接
while True:
n += 1
try:
response = requests.get(url,headers = head,timeout = 10)
except:
pass
else:
if response.status_code == 200:
return response
if n >= 10:
return False
构建一个常用的请求模块,在错误时重新请求,超过一定请求次数后跳过
folder_mkdir()
import os
def folder_mkdir():
if os.path.exists(os.getcwd()+'\\pic'):
pass
else:
os.mkdir(os.getcwd()+'\\pic')
folder = os.getcwd()+'\\pic\\'
return folder
创建一个空文件夹用于储存图片
get_data()
def get_data(item_host_url):
mode = 'thread' #多线程下载模式
folder = folder_mkdir()
item_response = Requests(item_host_url)
if item_response == False:
return
item_response.encoding = 'utf-8'
try:
item_data = re.findall('window.__ssr_data = JSON.parse\("(.*?)"\);\n window._UID_ = \'0\';',item_response.text)[0].replace('\\"','"').replace('u002F','').replace('\\\\','/')
except:
pass
else:
item_img_data = json.loads(item_data,strict=False)['detail']['post_data']['multi']
num = len(os.listdir(folder))
print(num)
for img_data in item_img_data:
img_url = img_data['original_path']
if img_url.find('jpg') >= 0:
img_fomat = '.jpg'
elif img_url.find('png') >= 0:
img_fomat = '.png'
else:
img_fomat = '.jpg'
num += 1
name = str(num)+img_fomat
if mode == 'thread':
t = threading.Thread(target = install_img,args = (img_url,folder,name)).start()
while True:
if len(threading.enumerate()) <= 25:
break
else:
install_img(img_url,folder,name)
请求图集链接,获取网页源码,从 <script> 标签中获取数据
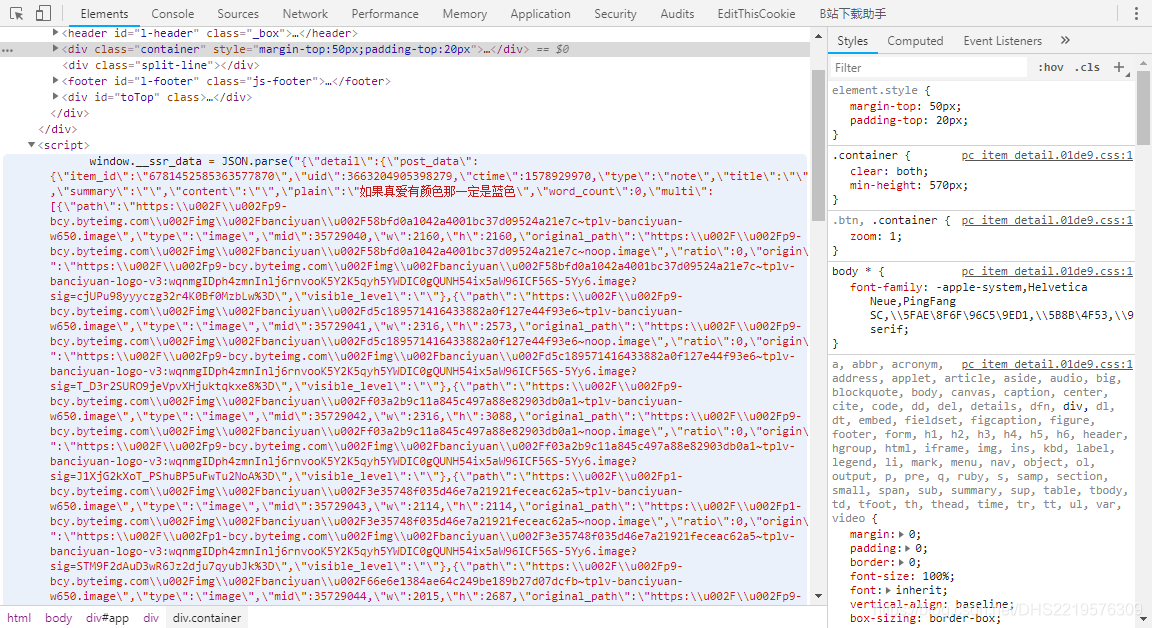
我们对这的数据进行分析,发现这是一个json格式的数据,我先对这些数据进行处理,让python的json库可以解析它们。
我们可以看到,一些双引号(”)的前面都有反斜杠(\),这就导致json库无法解析这些数据
str.replace('\\"','"')
将在双引号前用于转义的反斜杠给去掉,这样数据解析就没有问题了。但是在这些数据中有一些没用的字块”u002F”
str.replace('u002F','')
到这一步数据的处理就基本完成了。不过只是这样还是不够的,因为其中用于储存图片的链接中的斜杠是反斜杠,用requests请求的时候无法识别,所以我们还需要将反斜杠转化成斜杠
str.replace('\\\\','/')
我们分析这些数据,发现图片链接在【detail【post_data【multi】】】的结构下
最终处理完的结果是这样的

install_img()
def install_img(url,folder,name):
try:
img_content = Requests(url).content
except:
print('错误:{} 名称:{}'.fomat(url,name))
else:
open(folder+name,'wb').write(img_content)
传入三个属性,下载图片
构建下载函数是为了引进多线程下载的模式
通过while循环,获取线程数目加以限制,来防止线程过多导致被反。
while True:
if len(threading.enumerate()) <= 25:
break
枚举线程池中的线程数,如果大于25个就继续循环,阻塞主程序;小于25个则通过break跳出这一级的循环继续开线程下载图片。