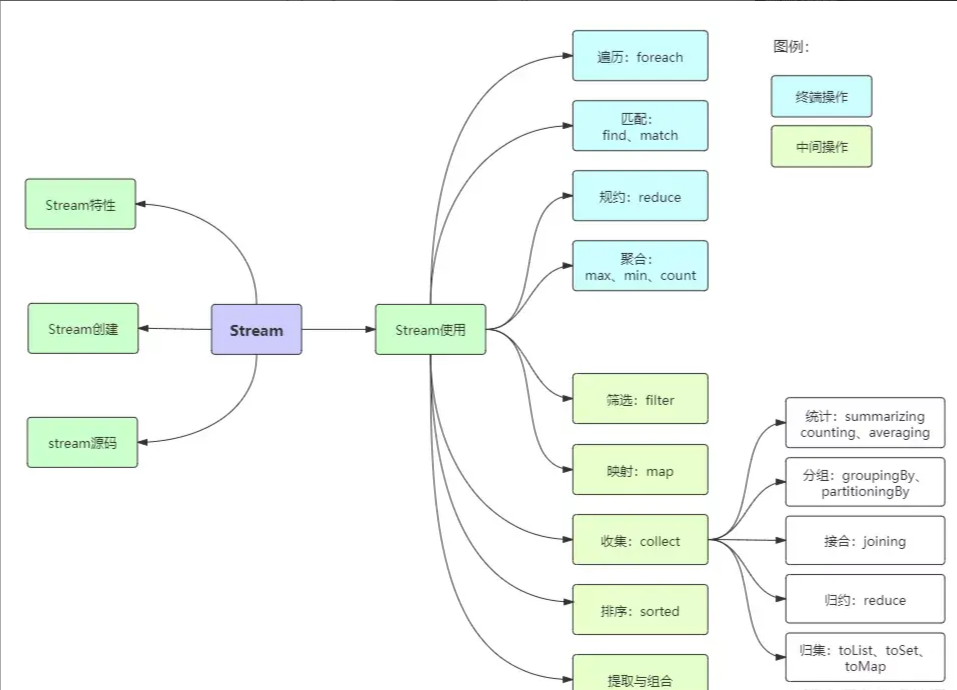
Java8新特性-Stream基础使用 Java8新特性-Stream基础使用 什么是Stream流 Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。 Stream可以由数组或集合创建,对流的操作分为两种: 中间操作,每次返回一个新的流,可以有多个。 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法… 2022-2-17 17:16 | 783 | 1 | 码一片天 1501 字 | 20 分钟 javajava8新特性Stream