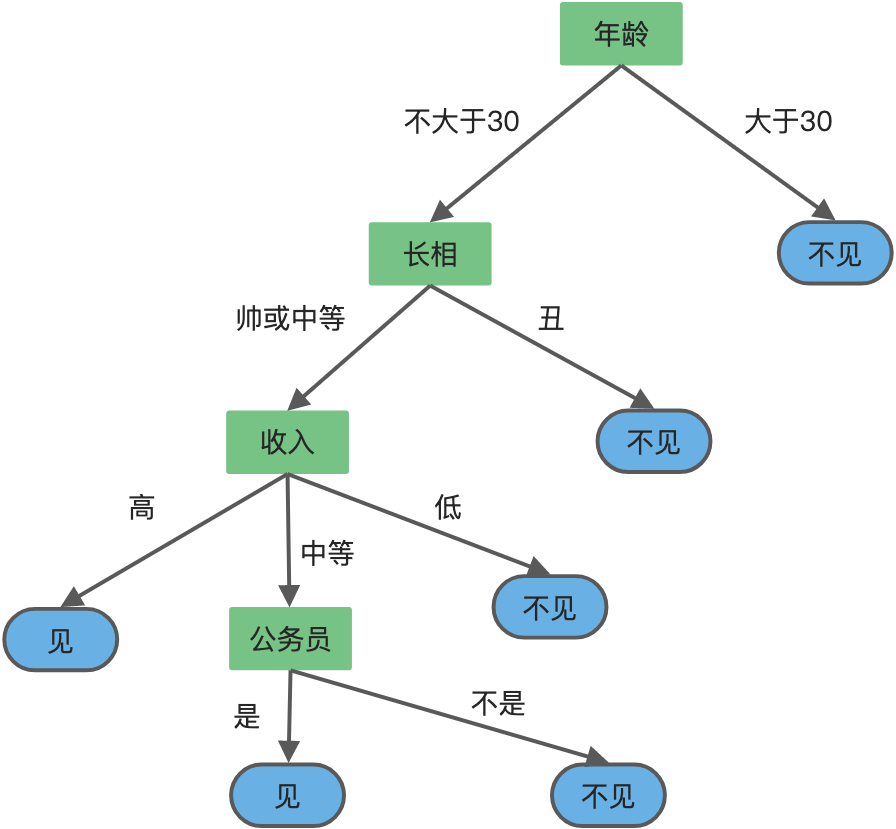
决策树 决策树是一个非常简单的算法,至少其思想是非常简单的。生活中我们经常会使用,看几个例子。 场景1,母亲给女儿介绍男朋友,下面是二人的对话: 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。 女儿通过年龄、长相、收入… 2022-3-18 15:37 | 1,597 | 0 | 码一片天 3430 字 | 15 分钟 决策树算法